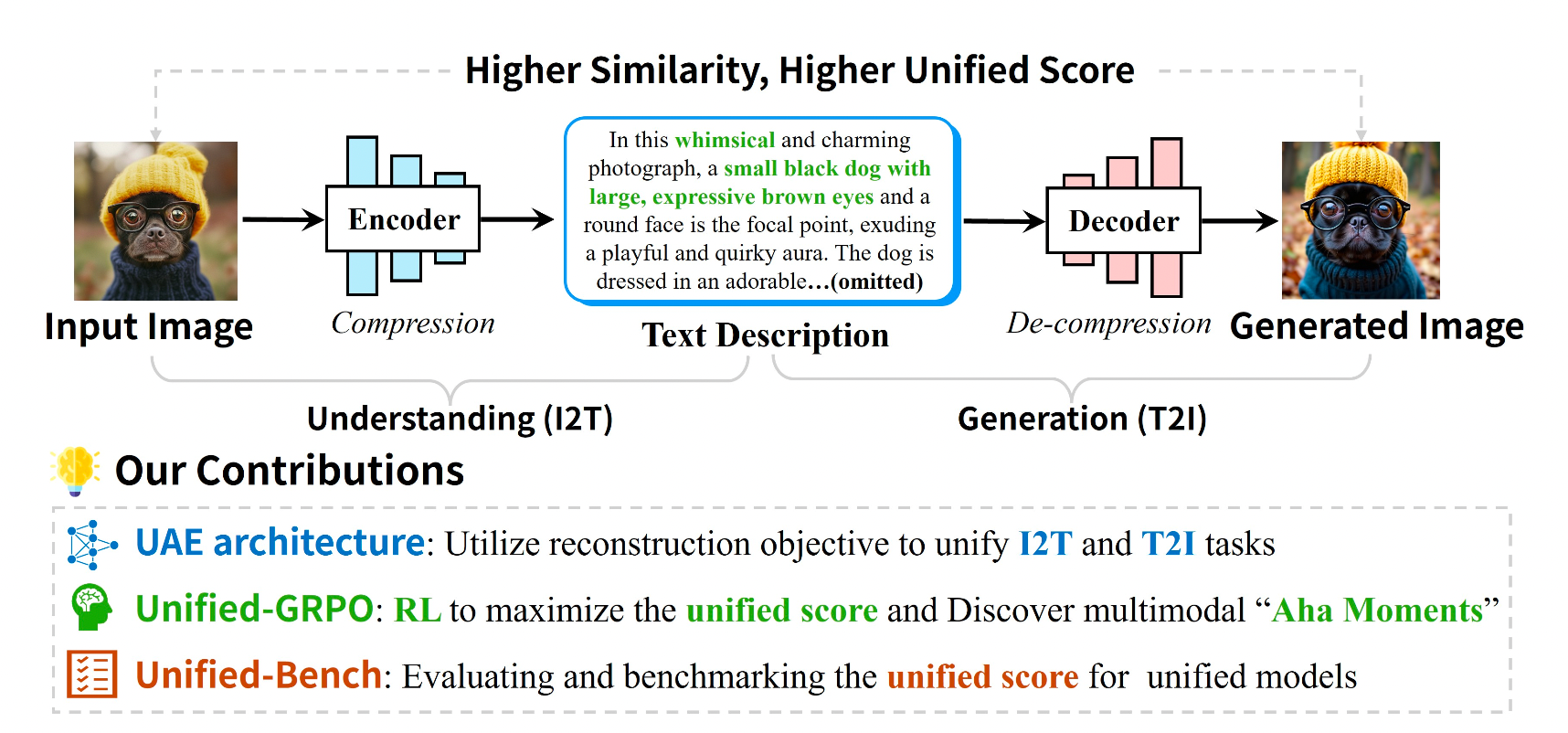
Unified Multimodal Model as Auto-Encoder
Zhiyuan Yan, et al.
CVPR, 2026
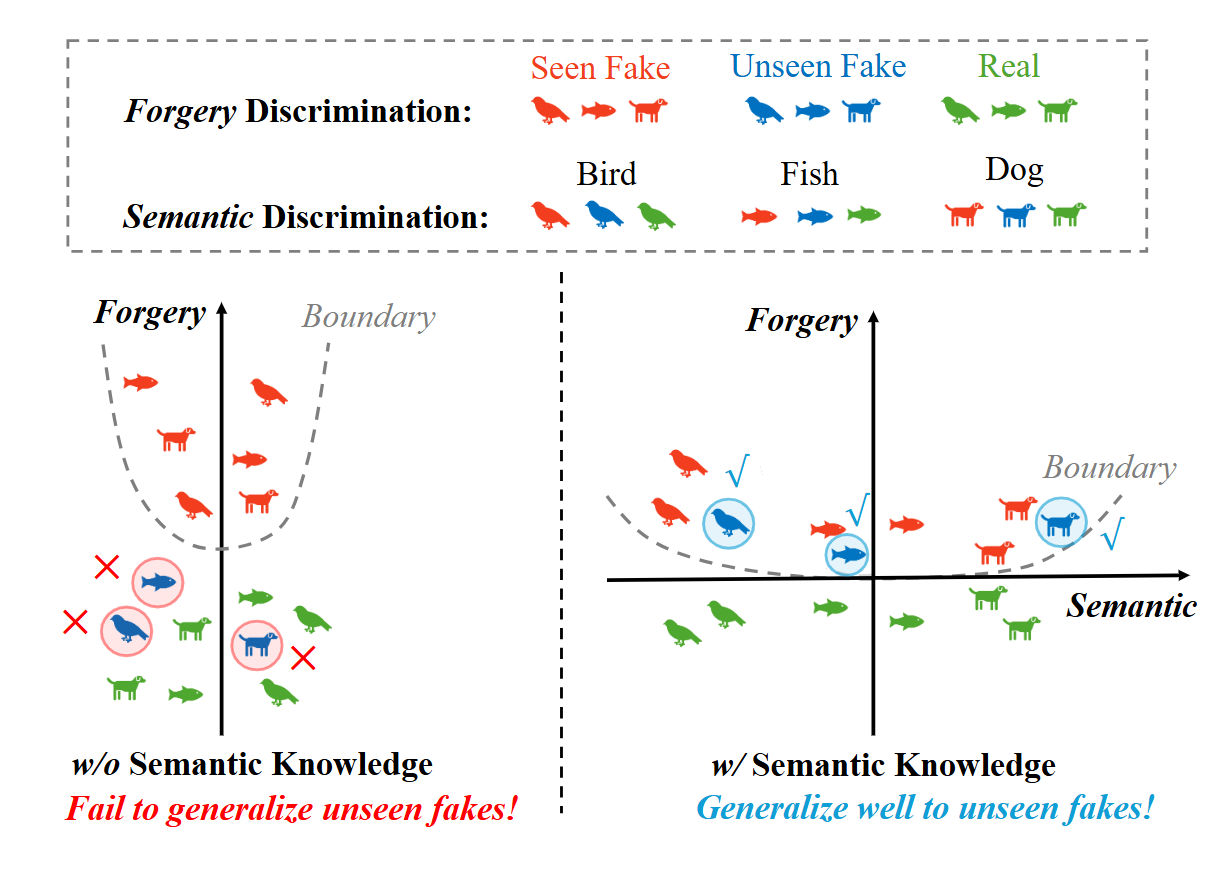
Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
Zhiyuan Yan, et al.
ICML, Oral 🏆, 2025
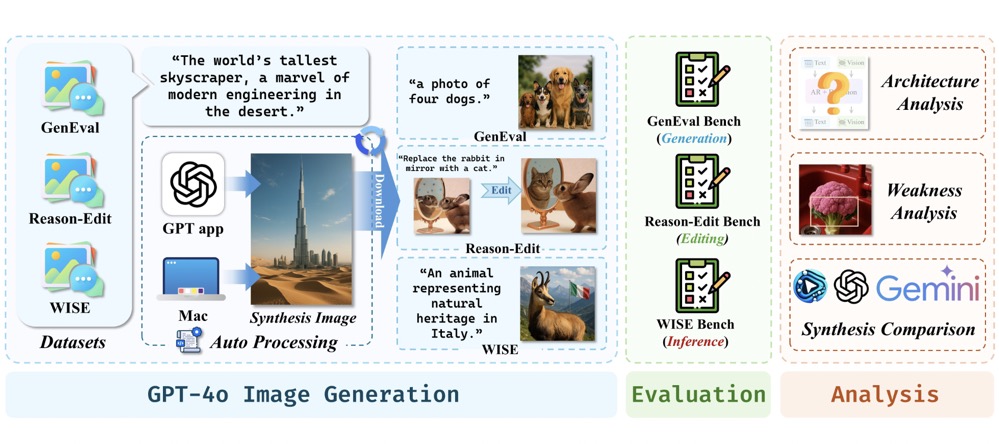
GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation
Zhiyuan Yan, et al.
Tech Report, 2025
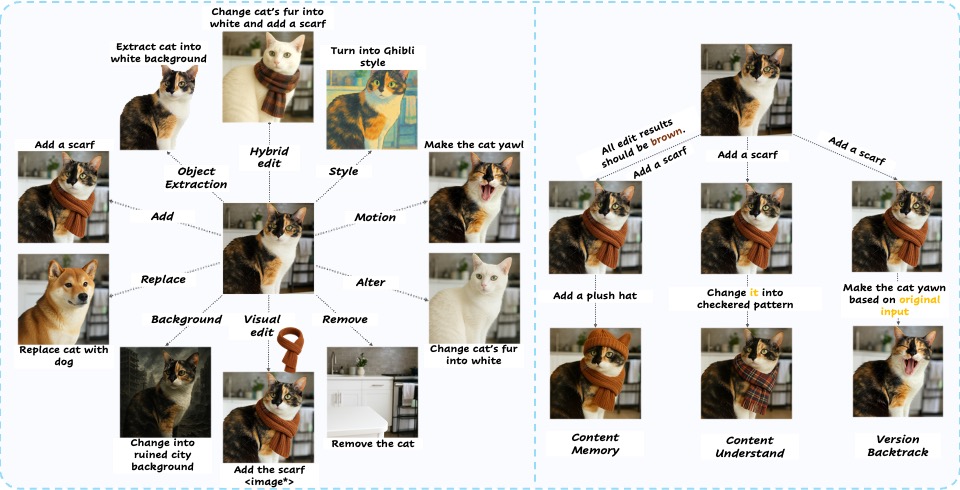
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye 🧑💻, et al., Zhiyuan Yan 🧑💻
NeurIPS, 2025
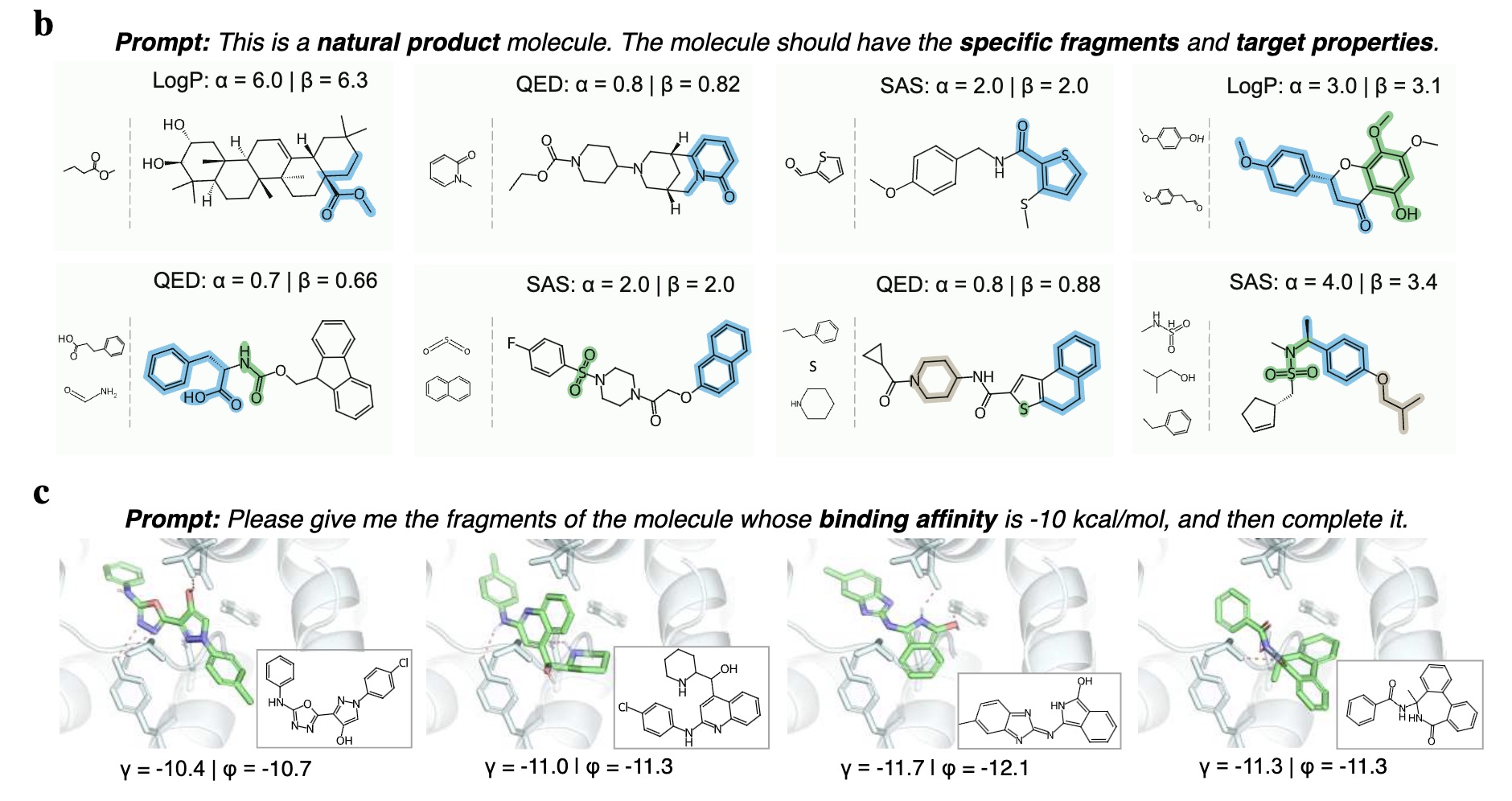
Navigating Chemical-Linguistic Sharing Space with Heterogeneous Molecular Encoding
Liuzhenghao Lv, et al., Zhiyuan Yan
Nature Communication, 2024
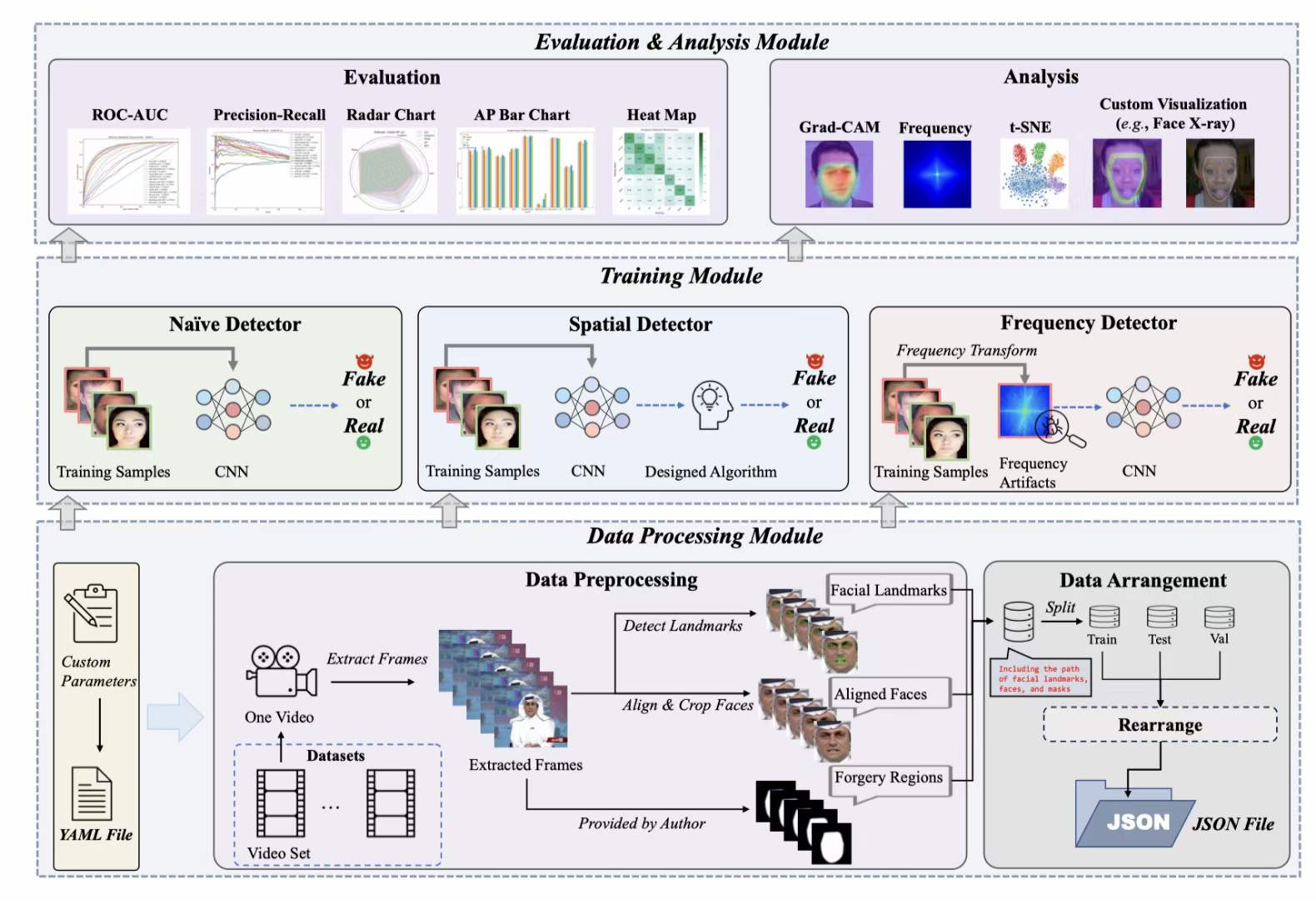
DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection
Zhiyuan Yan, et al.
NeurIPS, 2023